

En la actualidad, no importa en que lenguaje desarrollamos o como creamos nuestros proyectos, sin embargo mantener un control de versiones es muy importante para ser ordenado y para trabajar en equipo. En este tutorial, te mostramos como con GIT y Github podes tener un Control de Versiones paso a paso.
En otra oportunidad, y para usuarios que ya estan un poco más avanzados mostramos como hostear un gitlab propio:
Y es que si sos usuario de linux lo más probable es que tengas git instalado. Para comprobarlo podriamos hacer:
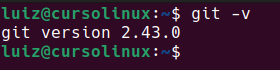
Ahora si vamos a la web https://git-scm.com/ podremos encontrar que la ultima versión es la 2.49, pero lo sierto es que para lo vayamos a hacer esta version esta muy bien.
Lo otro es que hay clientes graficos que tal vez te resultarian mucho más facil, pero es que si queres aprender a usarlo no hay nada mejor que la terminal, ademas que si te toca administrar un servidor es poco probable que tengas algo grafico andando. QUe pasa si solo ponemos git en la terminal y le damos enter:
Lo primero que vamos a hacer es simular una carpeta que es la raiz o base de nuestro proyecto. Por ejemplo vamos a usar cursolinux (vos ponele lo que quieras) pero creo que esta piola para armar un cursito ya que estamos 🙂
Luego nos vamos a crear una cuenta en https://github.com/
EL mail que usamos para esa cuenta tenelo presente por que vamos a utilizarlo en el siguiente comando dentro de la carpeta:

Los dos comandos anteriores son los necesarios para arrancar a trabajar con git y los puse global para que me sirva para «todo el sistema». Esto lo hago asi por que soy el unico que trabaja en mi compu y ademas no voy a crear para cada cosa un usuario de git diferente… en mi caso no me intereza y no hay nada «hackeable ni que ocultar». Estas acciones crean un archivo oculto que se llama gitconfig y que se encuentra dentro de la carpeta principal del usuario:

Ahora vamos a lanzar un ls (listar) para saber que tenemos dentro de cursolinux y no veremos NADA!

Un control de versiones nos sirve para evitar la duplicacion de archivos y proyectos, los famosos «esto asi andaba» o «copia de estaba andando». Entonces aqui ya podriamos lanzar visual studio, o cualquier editor de codigo para empezar a crear nuestro proyecto. Lo sierto es que tampoco hace falta, nosotros vamos a crear con nano un archivito de python para empezar a jugar:
nano index.pyy dentro pondremos:
print ("Bienvenidos al Curso de Linux")guardamos y todo se deberia ver como esto:

Ahora si ya tenemos un «proyecto» con lo cual vamos a iniciar git y decirle «desde ahora quiero un control de versiones»:
git init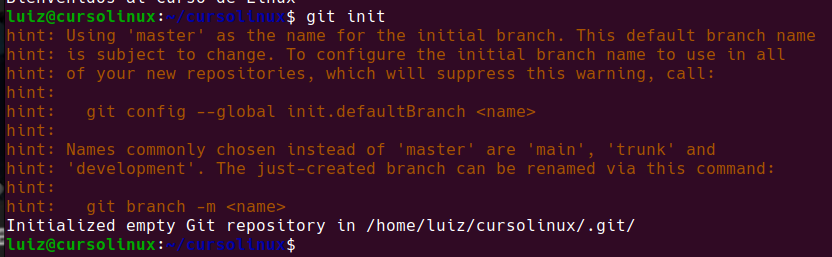
Todos los cursos y tutoriales los realizo en maquinas virtuales y la verdad no me preocupo demasiado ya que generalmente las borro y creo nuevas, pero en el caso de mi maquina utilizo en la terminal Oh My Bash que es para «decorar» lo que se ve en la terminal y tiene alguna que otra cosa interezante, por ejemplo, todo esto en mi maquina se ve asi:
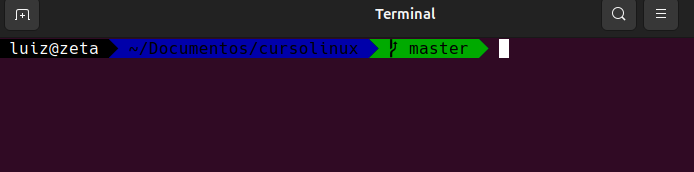
Como podes apreciar entre usar oh my bash o nada, la diferencia es que nos esta indicando la rama de git en donde estamos trabajando, que en este caso se llama Master ya que detecta la config, me parece genial utilizarlo para que puedan ver la diferencia. Además si yo ubiera inicializado git sin nada en la carpeta y luego ubiera creado index.py el master cambiaria de color por que ya esta funcionando el versionado:
Si ahora listamos vamos a ver el mismo archivo index.py pero «ojo» por que oculto hay una carpeta .git y la podemos ver con ls -la
Hasta aca estamos viendo la rama master (en github se denomina main y es la rama principal). ¿Entonces se le puede cambiar el nombre a una rama? claro que si. Aunque ahora solo estemos usando git esta bueno saber y hacer las cosas compatibles con github o gitlab. Para poner el nombre main usamos el comando:
git branch -m main
Hasta aca vimos el comando para la configuracion global, vimos como inicializar un control de versiones y vimos como cambiar el nombre a nuestra rama. Ahora vamos a ver el estado, ya que «ya tenemos algo de codigo» (aunque sea muy poco el index.py).
git status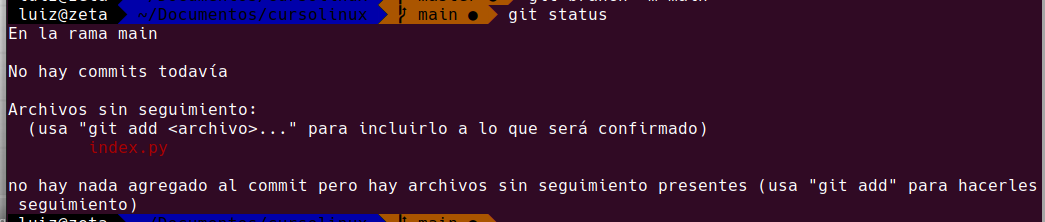
Como podemos ver nos indica «No hay commits todavia», y tambien nos dice que podriamos incluir el archivo index.py que aun no esta con ningun seguimiento. Para hacerle seguimiento a un archivo, que seria verdaderamente usar git, hay que agregarlo usando git add,entonces lo siguiente que vamos a hacer es:
git add index.pyal agregarlo vamos a ejecutar el git status nuevamente para ver que pasa:
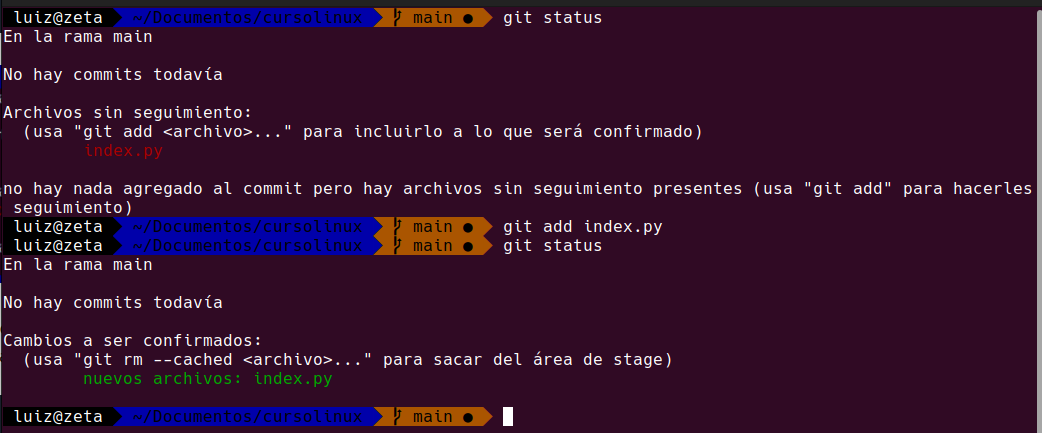
Como se puede ver luego de agregar index.py y ejecutar git status nuevamente, nos sigue diciendo que no hay commits pero que ya hay nuevos archivos que estan preparados para sacar a stage (escenario). EN castellano lo que estamos haciendo es sacarle una foto actualizada a nuestra carpeta para que git nos lo guarde, pero para eso necesita un «Comentario» y aqui viene el commits, que es decirle por ejemplo index.py es el primer archivo de este curso de git

la m en el comando es de mensaje. Si solo escribimos git commit se va a abrir un editor de texto (vim) que si no sabes usarlo seria complejisar el curso y por eso es que utilizamos la opción de poner un mensaje asi por que es mucho más rapido. Vemos tambien que la rama Main cambio de color, ya esta preparada y esta haciendo seguimiento al archivo index.py
Vamos a ver otro comando nuevo para continuar: git log el cual no va a indicar como vamos
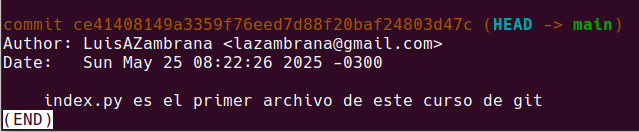
Vemos que tenemos los datos de un commit que tiene un autor y que ademas nos indica la fecha exacta en la que se creo. Los commits deben «decir algo» tienen que ser importantes para que en un futuro sepamos que quisimos hacer. Imaginen un proyecto grande no solo de desarrollo, por ejemplo de administración de redes. Si nosotros veiamos que en la configuración algo no andaba, lo encontramos y arreglamos, aqui el commit tendria que ser de tal modo que cuando alguien lo lea entienda lo que paso. Si comentamos absultamente todo tambien vamos a tener problemas yaq ue hay que nadar en comentarios para encontrar algo. Entonces hay que usar los commits de manera correcta.
Ahora vamos a proceder a crear un archivo nuevo que se llamará archivonuevo.py y dentro tendra el siguiente contenido:
nano archivonuevo.pyprint ("Este es un archivo nuevo y lo cree despues de index.py")Se va a ver asi:

Hasta ahora en la «rama main» tengo una «foto» que solo incluye index.py, si yo quisiera que mi rama avance y que tambien contenga a archivonuevo.py lo que tengo que hacer es agregarlo y comitearlo:
git add archivonuevo.py
git commit -m "agregando archivonuevo.py"
Como vemos si nuevamente ponemos git status nos va a indicar que la rama ya no tiene nada para hacer commit por que los archivos existentes ya estan agregados y comiteados (que seria: ya se le saco la foto y se le puso un comentario en cada vez que se saco la foto)
Si hacemos un git log nuevamente:
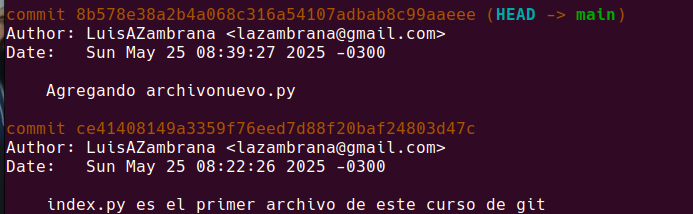
Estamos viendo una secuencia de fotos sacadas cada una con su commit.
¿Que pasa si modificamos un archivo en vez de crear uno nuevo?

Podemos ver que utilizando nano index.py podemos insertarle/modificar algo del archivo. Ahora que modificamos el archivo vamos a ver que pasa con git haciendo un git status:

Ahora nos indica que tenemos un archivo modificado que es index.py pero todavia no hemos enviado nada a git ni hemos hecho comentarios. Lo bueno de este estado es que podemos volver hacia atras a la version anterior del archivo. Para hacerlo solo escribimos:
git checkout index.py
Estamos practicando asi que tranquilo si algo no sale que de ultima se borra la carpeta y se vuelve a empezar.
¿Que pasa si tenemos un archivo con contraseñas que no quisieramos mandar a git o mejor dicho que no se tenga en cuenta?

Vamos a usar un nuevo concepto que es gitignore y sirve para charan charaaaannnnn ignorar archivos que no se deben subir ni tener en cuenta. Para esto hay que crear un archivo que tenga el nombre .gitignore
nano .gitignoreAdentro del archivo voy a poner lo que quiero ignorar, en este caso es un archivo que se llama contraseña.py asi que debo poner **/contraseña.py y quedará asi:


Vemos como luego de agregarlo y hacerle un comit, si ejecutamos el estatus no nos habla de contraseña.py ya que esta siendo ignorado, caso contrario, el estatus nos ubiera indicado que faltaba agregar y comitear a contraseña.py
Vamos a crear un cambio en archivonuevo.py, cualquiera:
echo "Asi podemos introducir texto sin editarlo" >> archivonuevo.pyNo hace falta entrar con nano archivonuevo.py escribir cambios y guardarlos, ya que rapidamente podemos ingresarle texto asi total es para pruebas.

Si hago un cambio git status me muestra cual es el archivo modificado, pero ¿Que se modifico?
Ahora utilizaremos git diff y el resultado será:

Como vemos se agrego algo al archivo. Claramente si ejecutamos python3 archivonuevo.py el «asi podemos introducir texto sin editarlo» no va a salir ya que para eso deberiamos editarlo y ponerle un print (pero eso ya es programacion y aca estamos viendo control de versiones).
Ahora para recordar un poquito vamos a volver a ejecutar git log
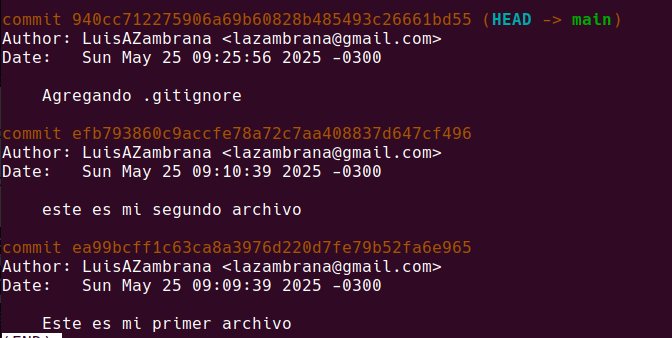
Mientras no hacemos commit con checkout pudimos volver hacia atras, pero ahora tenemos algunas cositas sin guardar, ¿que pasa si usamos el id del commit para volver a una version anterior?

Nos esta indicando que podemos hacer macana ya que hay cambios locales que no estan guardados y que van a hacer sobreescritos por checkout. Nos indica que deberiamos hacer un commit (sacar una foto) o un stash antes de cambiar de rama. Vamos a hacer un git add y un commit para luego continuar.
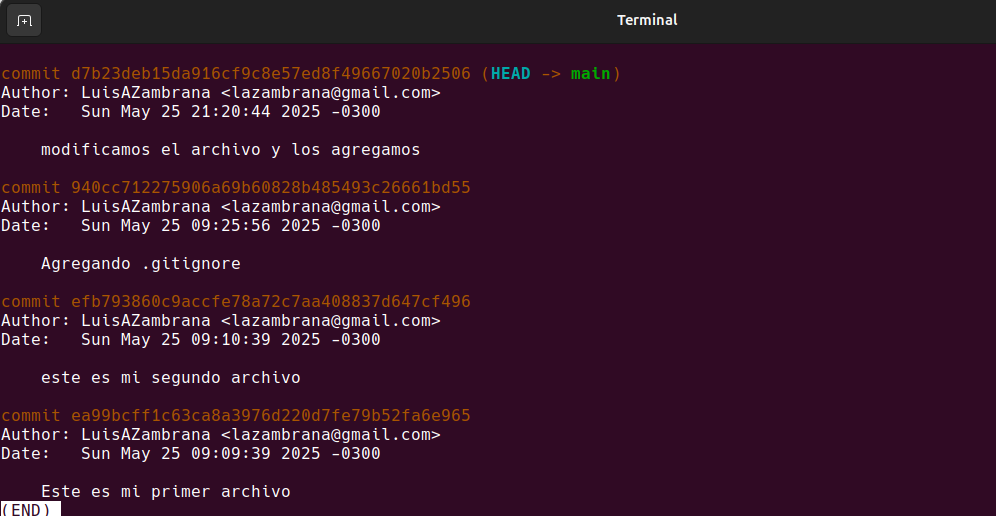
Como podemos ver en el restultado de git log tenemos un HEAD -> Main o cabecera del main, quiere decir que ahora estamos en este punto de la rama.
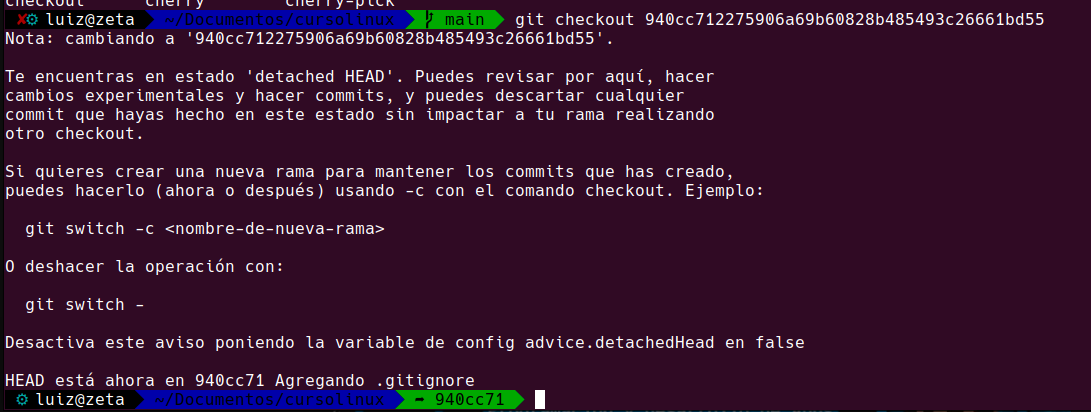
Y para que queremos cambiar el head? por que simplemente como estamos seguros que desde ahi para atras esta todo bien y para adelante no, queremos marcarlo de alguna manera como «la foto especial» nuestra cabecera de proyecto. De este modo podemos decirle al proyecto «aca estamos super bien» para delante vemos…..
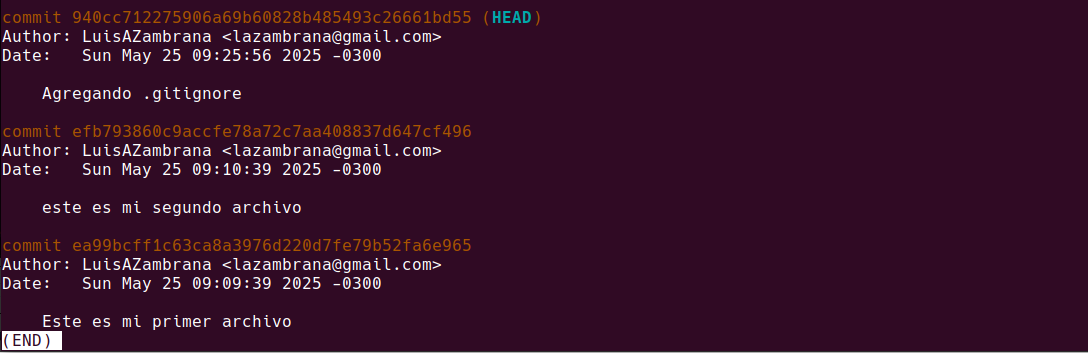
Hemos estado yendo y viniendo por la rama utilizando solo nuestra pc, no hay github ni gitlab aun.

Vemos que el head cambio pero que si listo los archivos siguen estando, nada se borro! Es importanticimo que antes de hacer cosas en produccion podamos practicar muchisimo!
Ahora voy a modificar el archivonuevo.py agregandole una simple linea de texto, lo voy a agregar y hacer un comit para que veamos junto el log:

Como podemos ver ya no estamos sobre main desde hace dos capturas….. HEAD ESTA DESACOPLADO pero en ingles seria Detached. Cuando hicimos el checkout le estabamos diciéndo a Git: “Muéstrame este commit específico”, pero sin moverte a una rama. ¿Por qué es importante saber esto? En este estado:
- Podemos ver el código de ese commit.
- Podemos modificar archivos, peroooooooooooo si hacemos nuevos commits y luego cambiamos de rama, los podemos perder.
Ya se, ni que fuera un mono tanto ramas y ramas……
Podemos decir que si estamos trabajando en un codigo podemos optar por trabajar en una rama «desa» (que seria como desarrollo) y una vez que estamos bien hacerla master o main y cambiarnos entre una y otra. ¿Pero como creamos una rama?

y luego nos vamos a la rama main:

Documentar es super importante y si estamos trabajando en equipo ademas de documentar tenemos que comunicarnos ya que es muy muy muy común que hagamos pequeñas animaladas cuando arrancamos y nuestros compas nos quieran matar.
De aca en adelante voy a usar un poco de visual code para mostrar los archivos, asi que puedo escribir en la carpeta code . y se abrira la carpeta con los archivos dentro:

Esto que estamos viendo es cuando, bastantes capturas atras utilizamos un echo para agregar una linea sin usar un editor como nano. Estoy en la rama MAIN, como hago para cambiarme de rama y ver que pasa en el otro lado?

al cambiarnos de rama, y sin ni siquiera haber tocado a visual estudio, cuando lo vayamos a abrir veremos:

Es una genialidad, pero como les decia: «Cuidado con las genialidades por que sino aprendemos a usarlas correctamente hacemos lio».
Y si estoy en un grupo de trabajo y cada usuario tiene su rama creada? puffff que tremendo, pero puede pasar. Con el comando git branch veremos cuantas ramas existen y en cual estamos parados:
git branch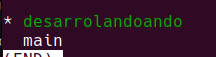
Entonces ahora voy a hacer lo siguiente: «Suponiendo que siempre estoy creando codigo en la rama desarrollandoando y que desde ahi creo la rama productiva» lo que voy a hacer es ahora generar una copia de desarrollandoando como main:
git checkout -b mainPero:
fatal: una rama llamada ‘main’ ya existe
Claro! no puedo renombrar algo si ya existe. Esto ubiera servido si main no existia, pero no es asi. Entonces como podemos hacer? Tenemos dos opciones:
git checkout main
git reset --hard desarrollandoandogit checkout main: te mueve a la rama main.
git reset –hard desarrollandoando: mueve main a apuntar al mismo commit que desarrollandoando, sobre-escribiendo su historial y archivos.
Si en main teniamos commits unicos te va a sonar el comentario «CAGAMOS». la idea es justamente que practiques!
La segunda opción y de paso aprendemos algo nuevo es:
git branch -D main
git checkout -b main git branch -D main elimina la rama main, mientras que con git checkout -b main crea desde donde estamos parados una copia en la rama main nuevamente.
Hasta aca jugamos bastante y solo con muy pocos comandos. Vamos a crear en github un repositorio con cualquier nombre, yo voy a usar «cursolinux» y lo voy a poner publico para poder jugar:
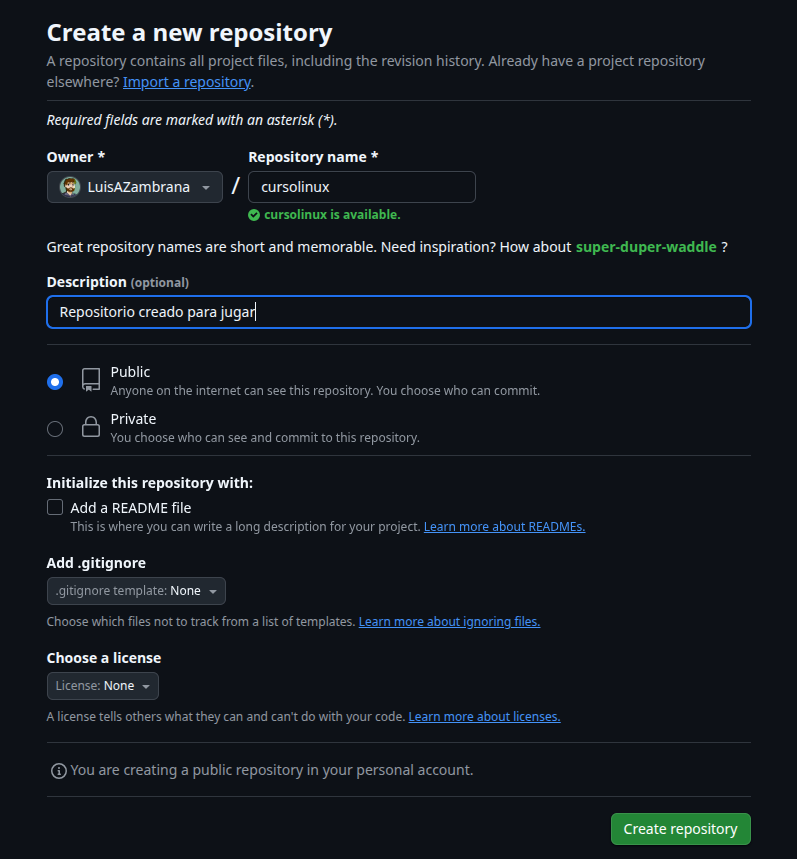
Al hacer clic sobre Create Repository vamos a ver:
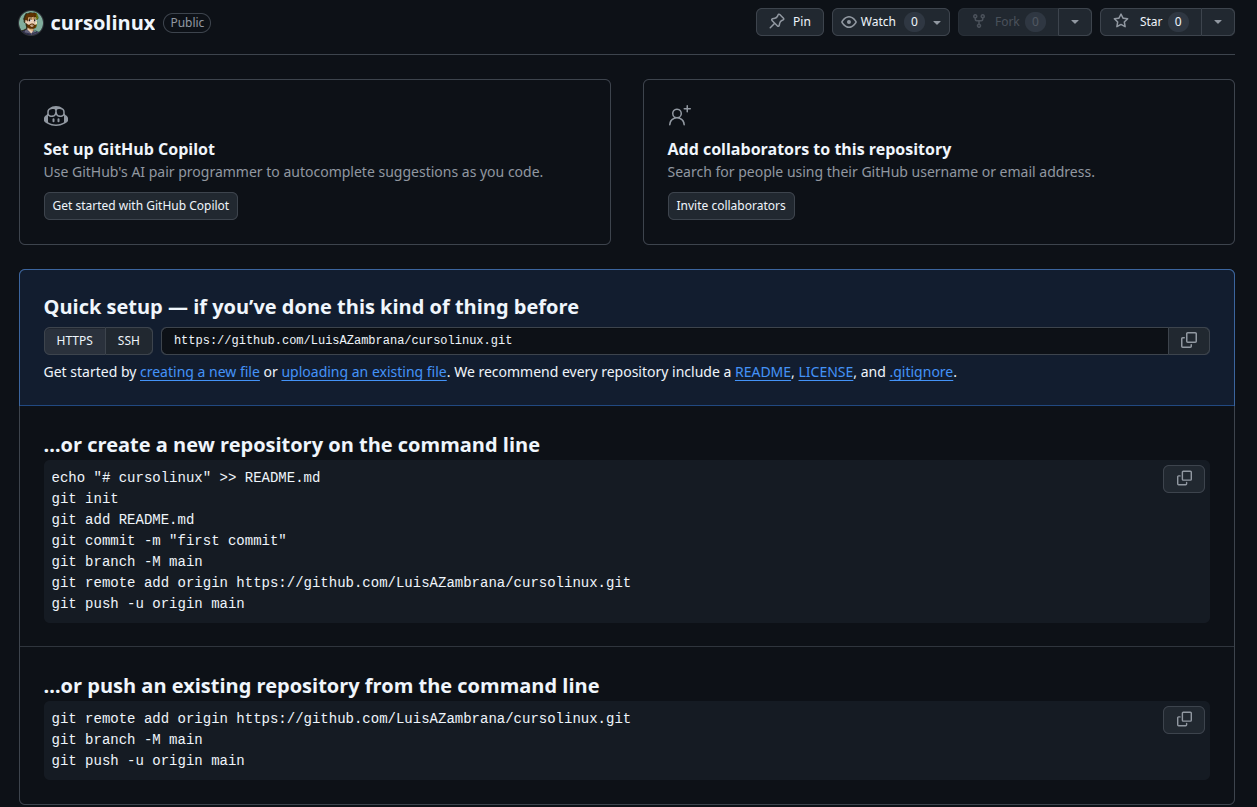
La imagen anterior son ayudas para trabajar con el repositorio por parte de github, podemos ver que nos indica crear un readme.md que es un archivo con indicaciones generales «de que se trata el proyecto?», tambien nos muestra como hacer un commit, crear la rama main, y luego esta remote y push que lo vamos a ver a continuación.
Estamos exactamente aca:
Otra cosa que debemos saber es que antes (2021) se podia configurar el usuario y la contraseña, pero eso ya no es posible, se necesita un token. Para crear un token debemos ir a https://github.com/settings/tokens
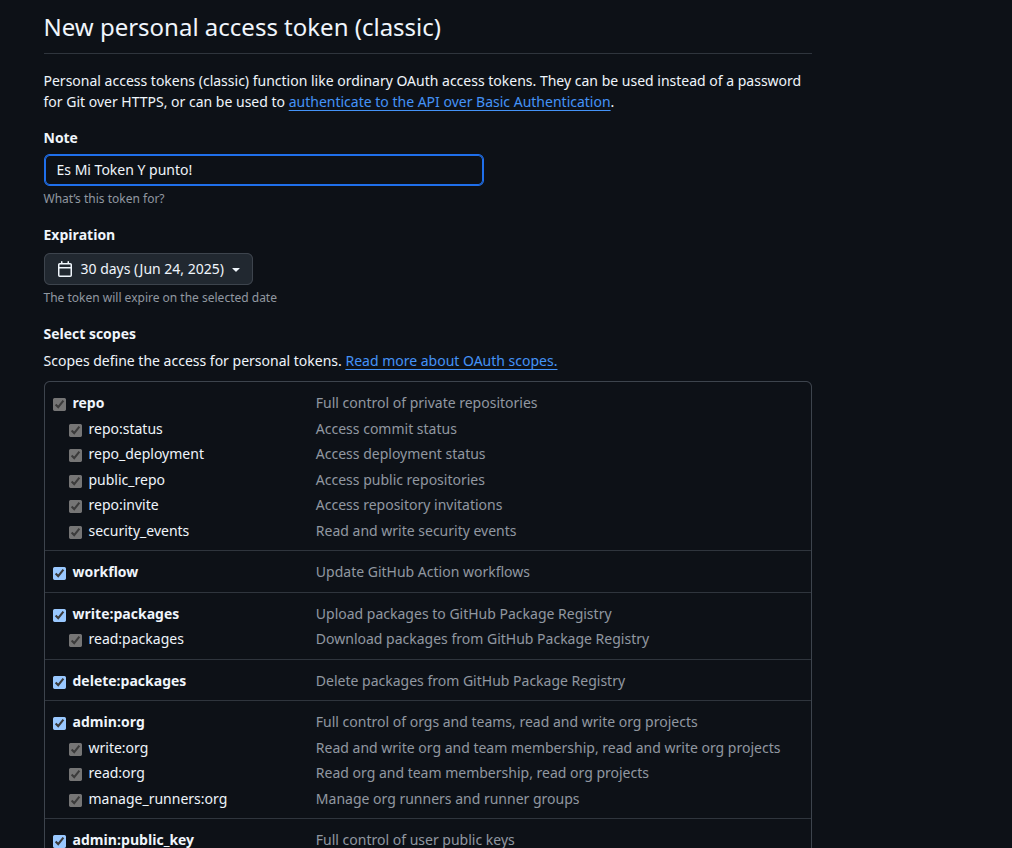
Si miramos bien podemos darle permisos al token para hacer o no un monnnnntoooon de cosas!! Es muy importante que si nos toca administrada un servidor de git sepamos exactamente lo que hacemos!
y ahora tenemos dos opciones:
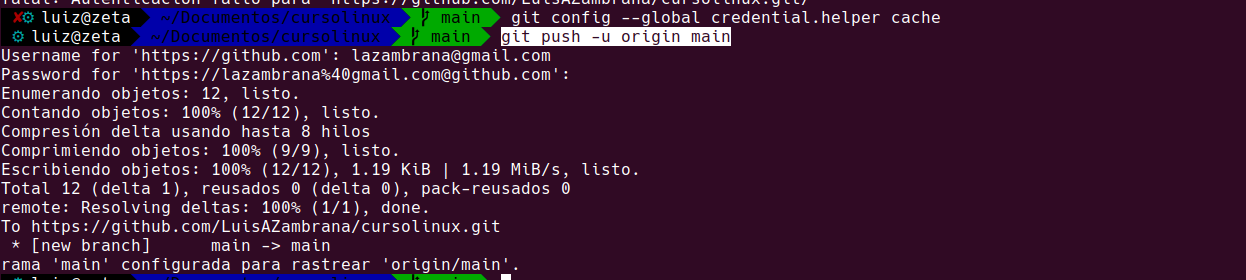
Guardar el token dentro de credential.helper (esto hace que no nos este pidiendo a cada vez que hacemos un push el usuario y la contraseña)
git config --global credential.helper cacheLuego hacemos:
git push -u origin mainNos pide el usuario (mail) de github y luego la contraseña (aca ponemos el token)
Otra opción para github es usar el ssh key que tengamos! Si no sabes como en este tutorial lo podes encontrar:
Nos dirigimos a https://github.com/settings/keys
A veremos:
Ahora en nuestra maquina hacemos:
cat ~/.ssh/id_rsa.pubY el texto que nos devolvio lo pondremos en New SSH Key y luego:
git remote set-url origin [email protected]:LuisAZambrana/cursolinux.git
ssh -T [email protected]Ahi nos pedirá autenticación y luego podremos hacer un push normalmente. Si me preguntan a mi, lo del sshkey yo no lo uso, con el token estas sobrado, tenes más seguridad y fecha de caducidad por «si colgas».
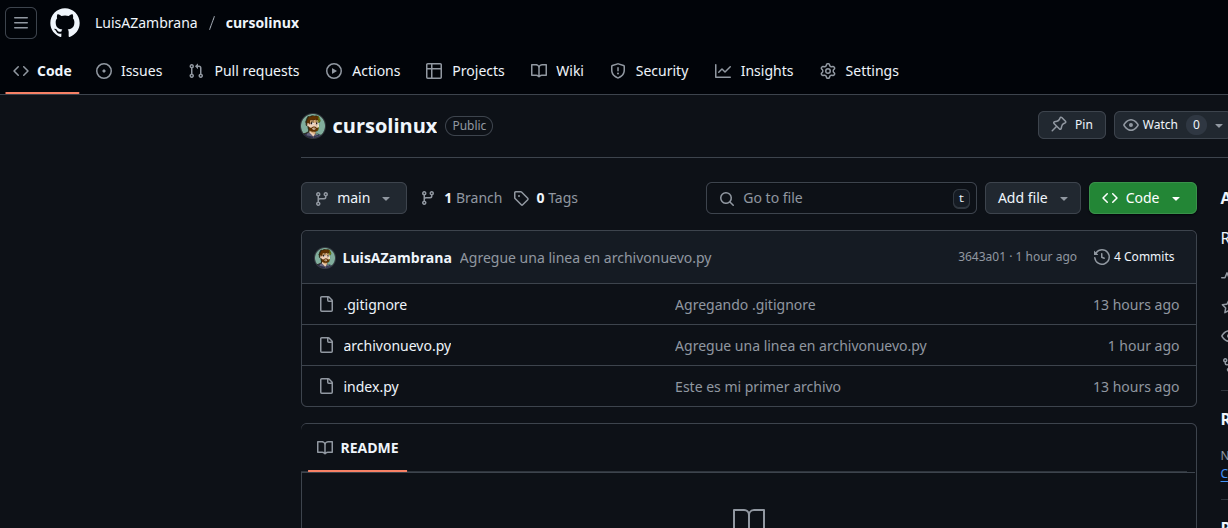
Como vemos tenemos los archivos arriba en la rama Main y dice 1 branch (una rama sola) por que la rama desarrollandoando no la subimos. ¿Podriamos? SI! lo hacemos de esta manera:
Cambiamos a la rama desarrollandoando:
git branch desarrollandoando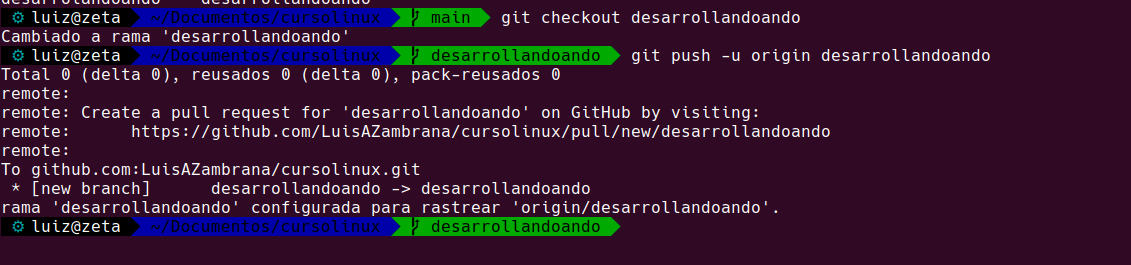
ya fuiste a ver a github?
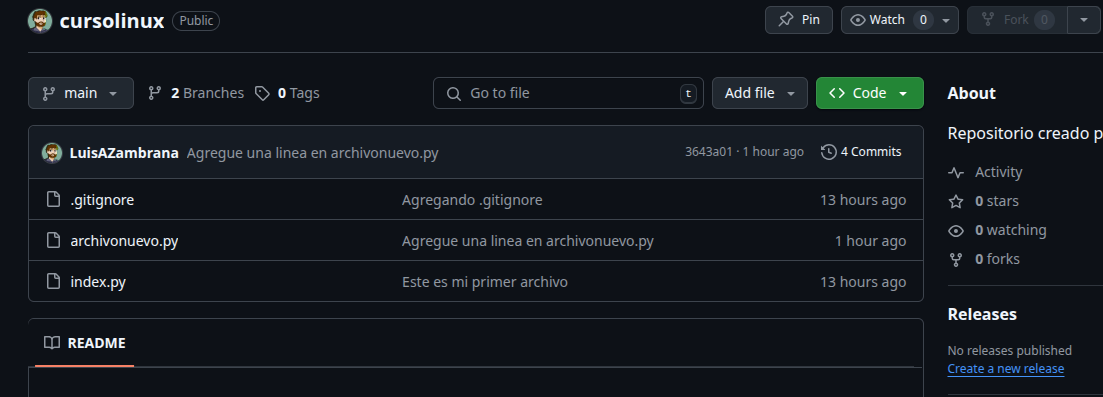
y si hacemos clic en 2 branches veremos:
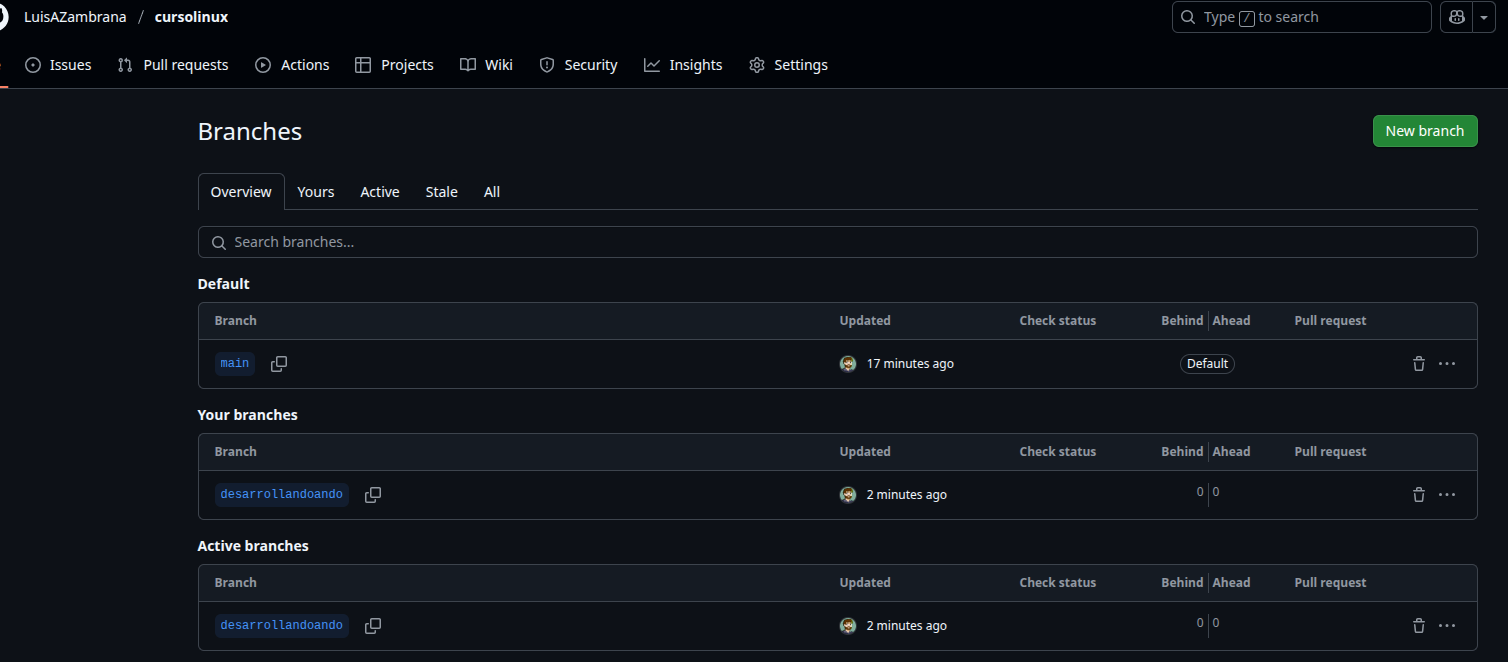
Cada vez que nos movemos de rama en rama podemos hacer push (enviar) sobre github. A los usuarios o compañeros les tendremos que decir para que es cada rama, por eso es importante el README.MD
git branch -aCon este comando vamos a ver cuales son las ramas que tenemos remotas:
Ahora nos vamos a asegurar que tengamos las dos (o la cantidad que sea) ramas actualizadas:
git fetchy ahora si recoramos que antes hicimos diff para ver diferencias o mejor dicho comparar, vamos a hacer lo mismo con las ramas:
git diff main..desarrollandoandoEn el caso de que haya algo se los va mostrar! y otra forma es ver que archivos cambiaron:
git diff --name-only main..desarrollandoandoAhora vamos a crear un Pull Request
1 – Revisar cambios antes de mezclar: Te permite ver qué hiciste y compararlo con la rama principal (main) antes de aplicar los cambios. Con esto podemos Revisar nuestro propio trabajo y ver si hay conflictos, además de confirmar que no estamos rompiendo nada.
2. Guardar historial de cambios: Un Pull Request queda registrado en GitHub como una discusión con: «Qué archivos cambiamos», «Qué líneas agregamos o eliminamos», «Comentarios, razones, notas» y todo esto es nuestro HISTORIAL DE VERSIONES, o sea que nos ayuda a responder:
“¿Por qué cambié esto?”, “¿Qué día lo agregué?”, “¿Qué problema resolvía?” (que mas queres mejillones?)
3. Buenas prácticas: Aunque estemos solo, usar Pull Requests nos permite trabajar por ramas (feature-x, fix-bug, etc.), fusionar cambios ordenadamente y mantener un flujo limpio y profesional. (ya te dijeron desarrollador junior? buenoooo ahora le podes decir que SI pero Ordenado 🙂
4. Colaborar en el futuro: Si mañana trabajamos en equipo, el Pull Request es la herramienta número uno para que otros revisen nuestro código, hagan comentarios y aprueben o pidan cambios antes de unirlo a main.
El pull request se hace desde pulls de tu repositorio: https://github.com/LuisAZambrana/cursolinux/pulls
Pero atención «Hasta aca no tenemos ninguna difenrecia entre las ramas» y si queremos hacer un pull request debemos tener diferencia. Para seguir con la practica vamos a cambiar a desarrollandoando
git checkout desarrollandoando
echo "print ("Este es un cambio nuevo")" >> archivonuevo.py
git add archivonuevo.py
git commit -m "Agregue una linea en archivonuevo.py"
Ya con los cambios agregados a la rama desarrollandoando voy a hacer un push en github:

Ahora puedo volver a mi rama main con git checkout main
Ahora si en pulls vamos a crear un pull request
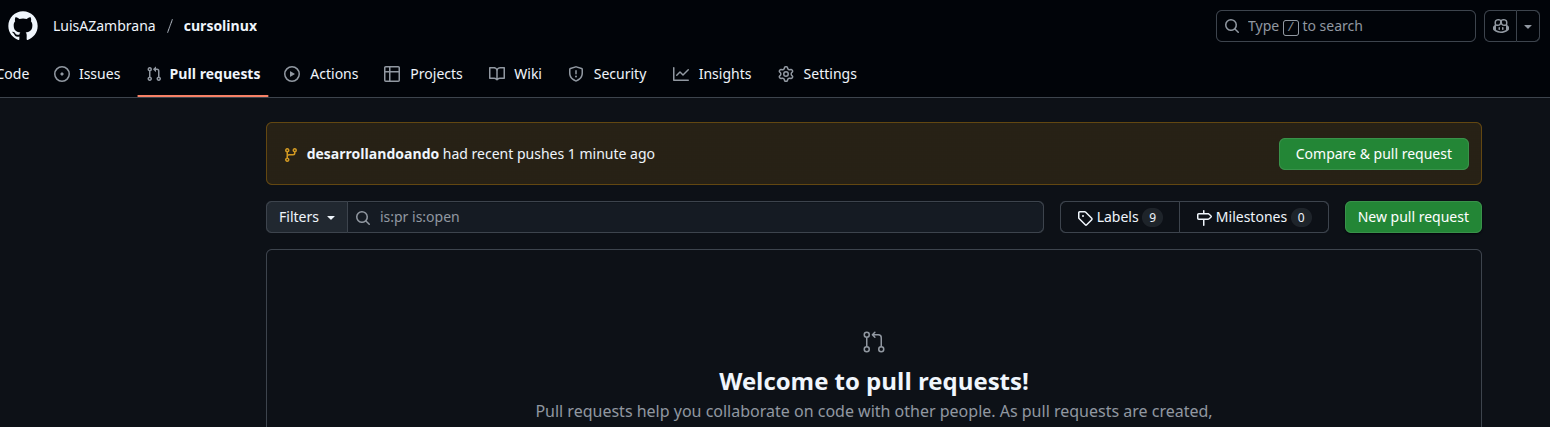
Ya vemos que nos indica que desarrollandoando tiene un push reciente, podemos comparar y hacer el pull request
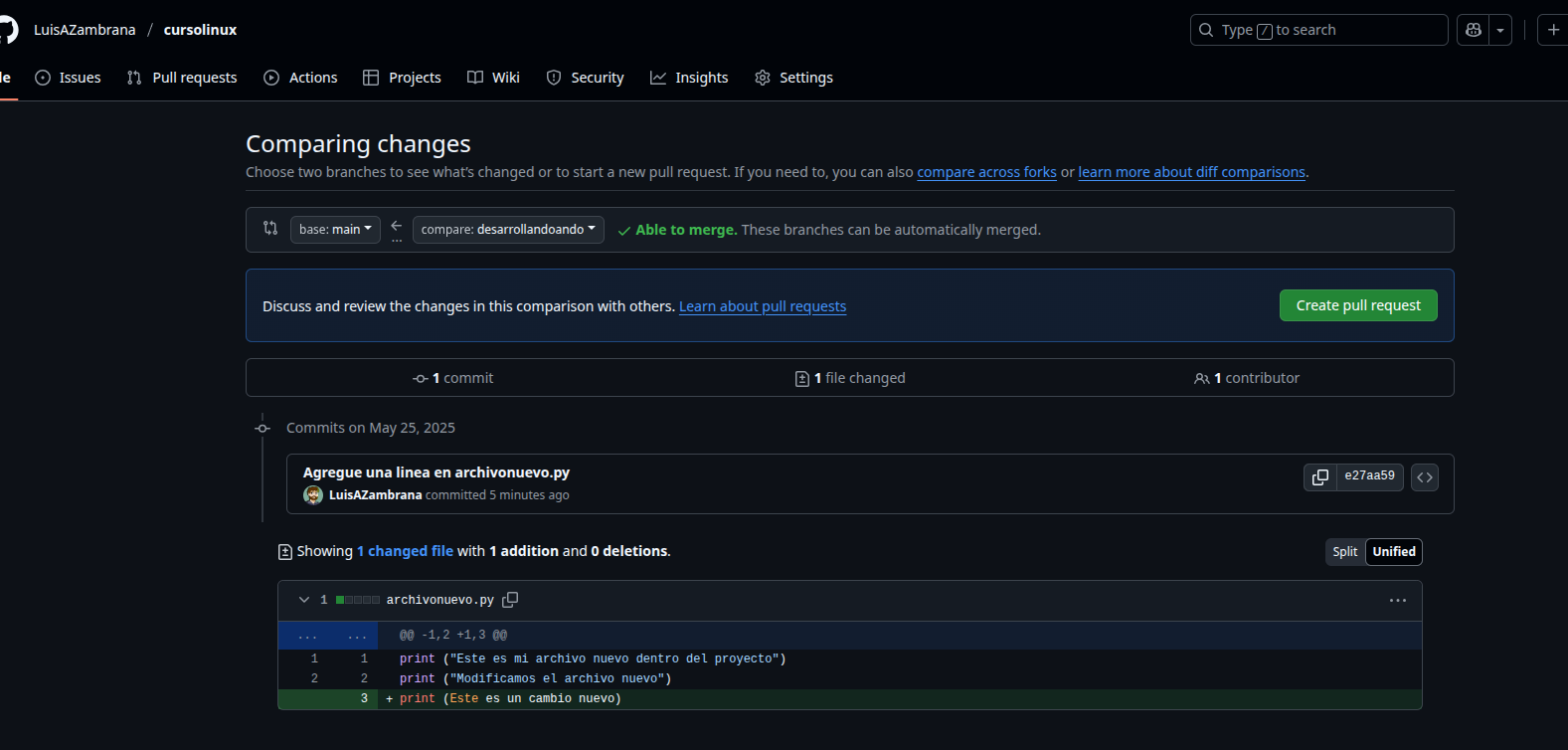
Vemos que dice base: main <–compare desarrollandoando, esto a mi fue una de las cosas que me costo, por que no INTERPRETABA la flechita. Ahi precionamos Create Pull Request y veremos:
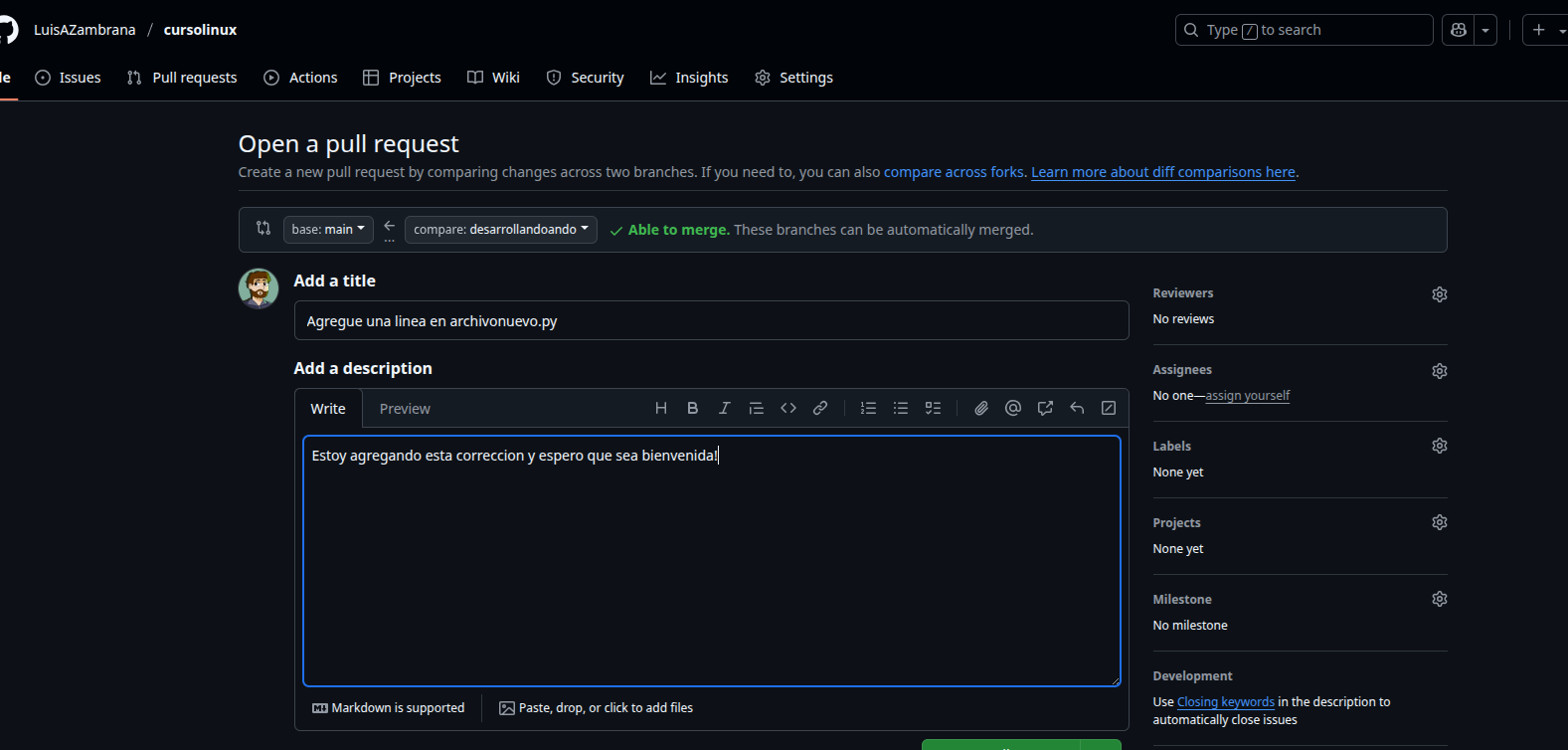
Como vemos podemos agregar una descripcion del pull request y luego crearlo. Al crearlo podemos ver:

Hasta aca como es solo una linea nos dice que no hay conflictos y que si quisieramos podemos FUSIONAR las ramas y esto seria hacer un MERGE. Al fucionar las ramas quedaran iguales y ya podriamos borrarla si es que queremos.
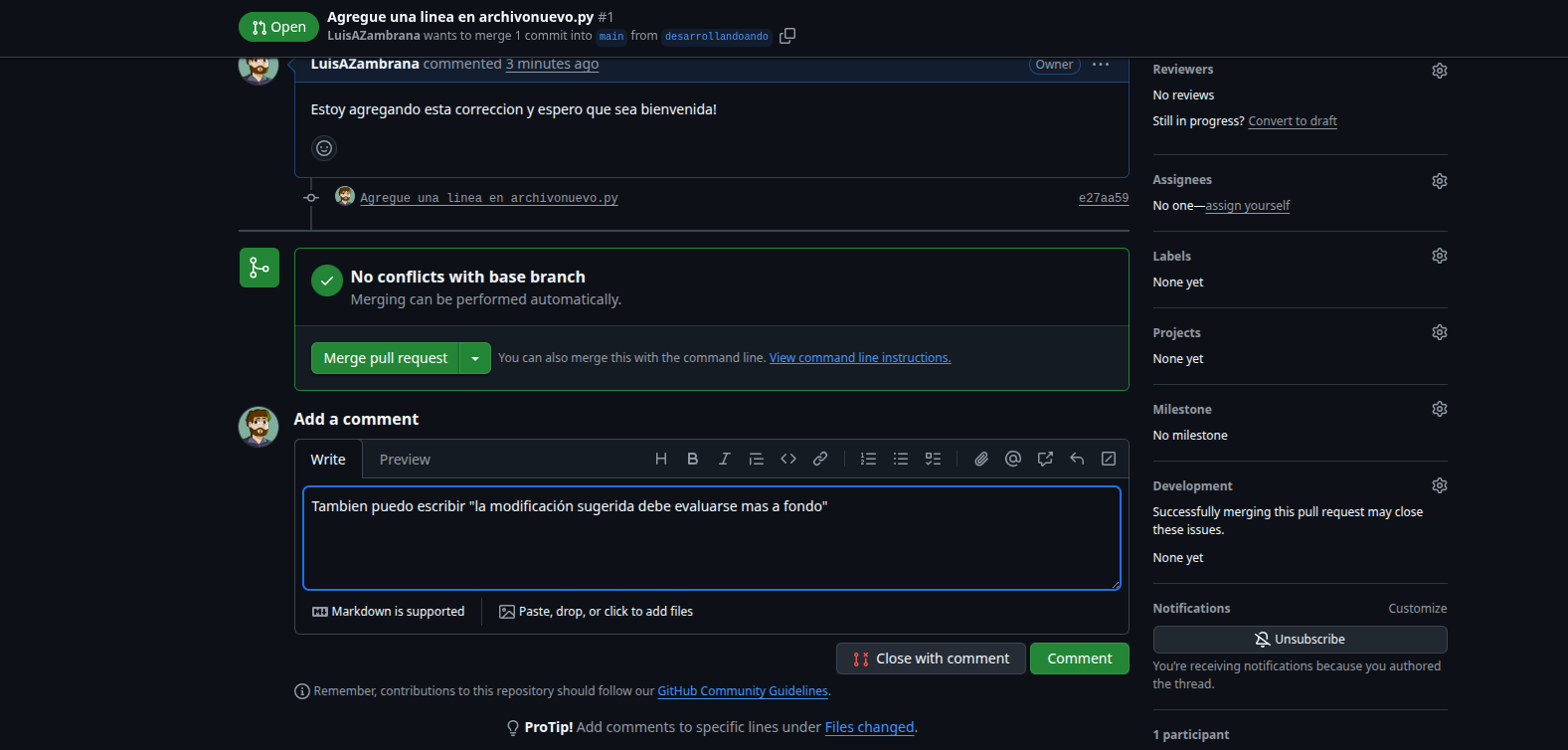
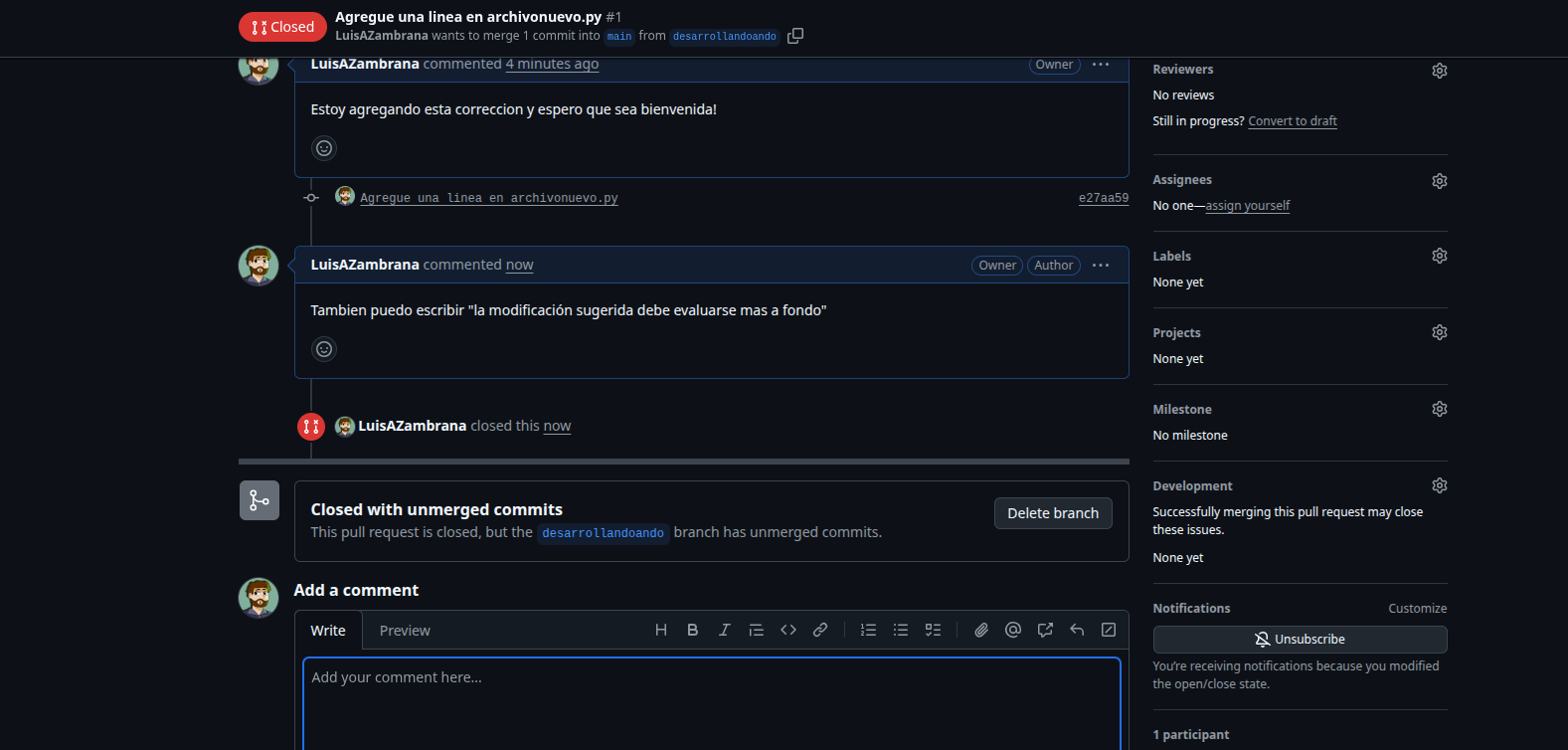
Y asi podemos seguir modificando por que por más que no se hizo un merge los cambios siguen estando en la rama desarrollandoando y puedo solicitar una reapertura (re open) del pull request, eliminar y mejorar la linea pra que si la tomen como colaboracion, etc. Generalmente si uno «colabora» trata de hacer las cosas bien, de lo contrario lo real es que te quiten del grupo.
Falta muchisimo más, pero esto es un monton para iniciar y practicar, asi que espero que te haya gustado esta introduccion a git y github!


